01 · Context
“We know there’s money out there. We just don’t have a grant writer.”
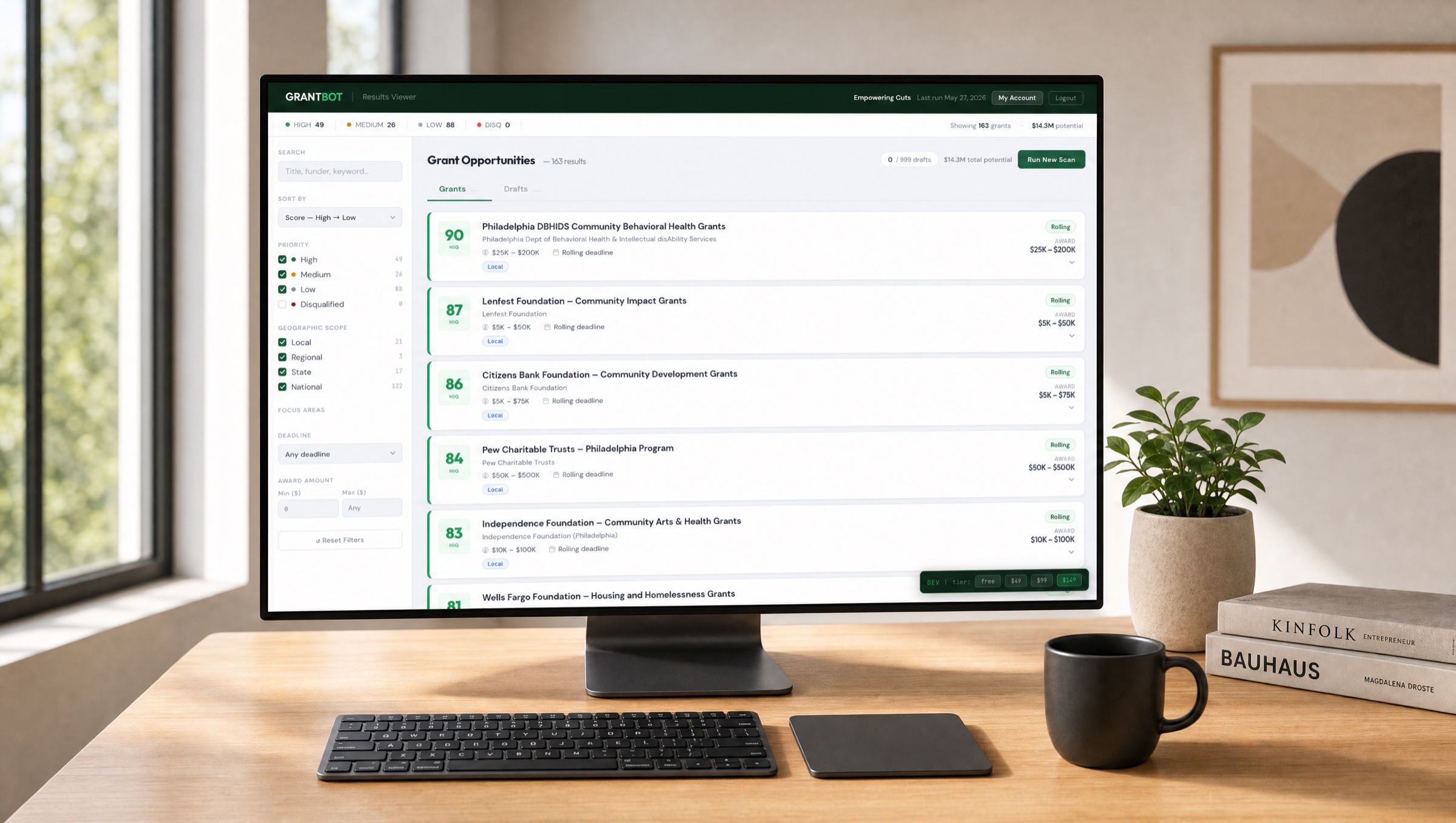
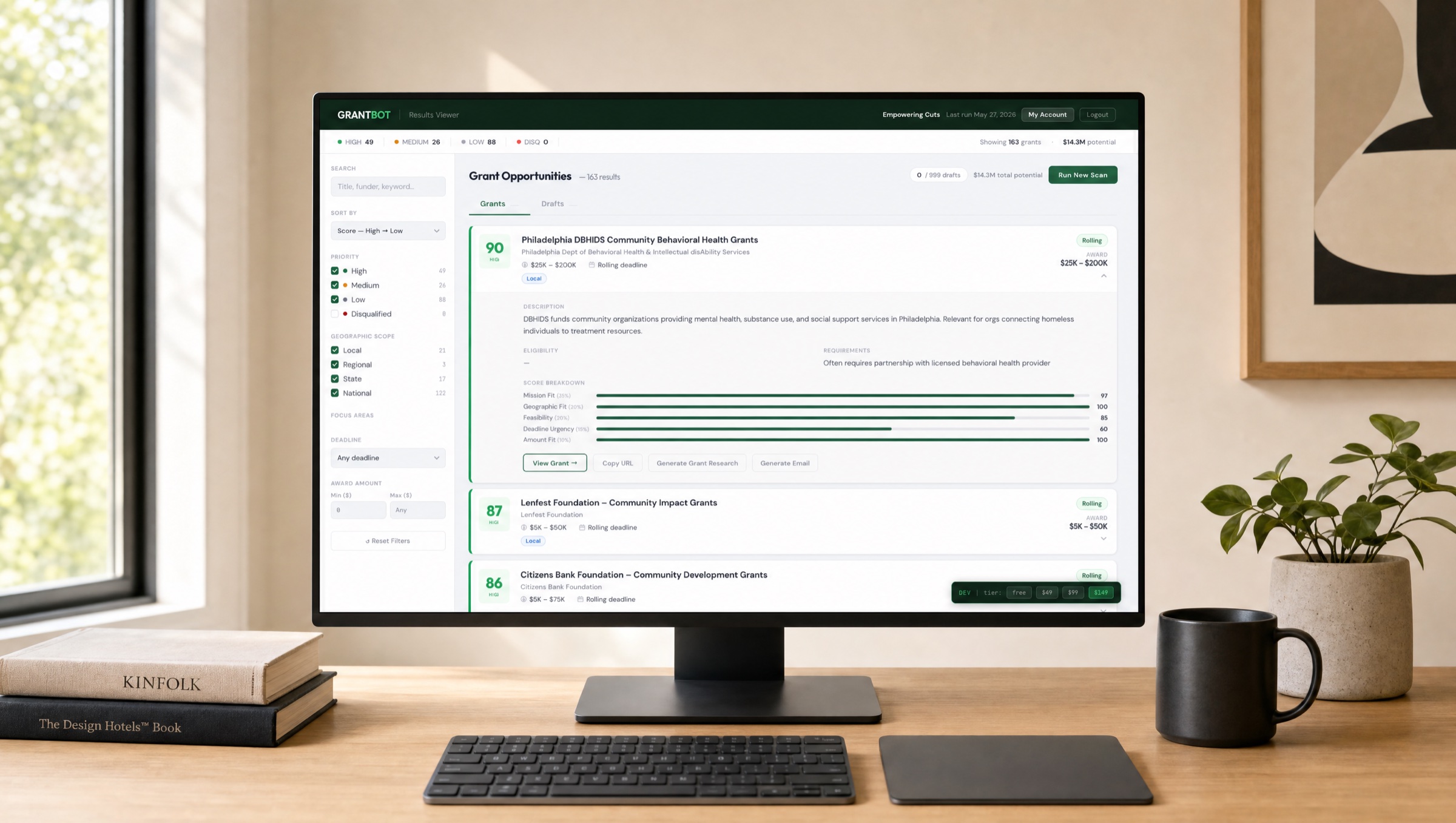
Small Philadelphia nonprofits sit between two bad options: pay a grant writer $3–5K/month they can’t afford, or have the ED moonlight as the grant writer at 11pm after a full day of program work. Both lead to the same outcome — the same five obvious foundations get applied to over and over, and 90% of the available funding pool never gets touched.
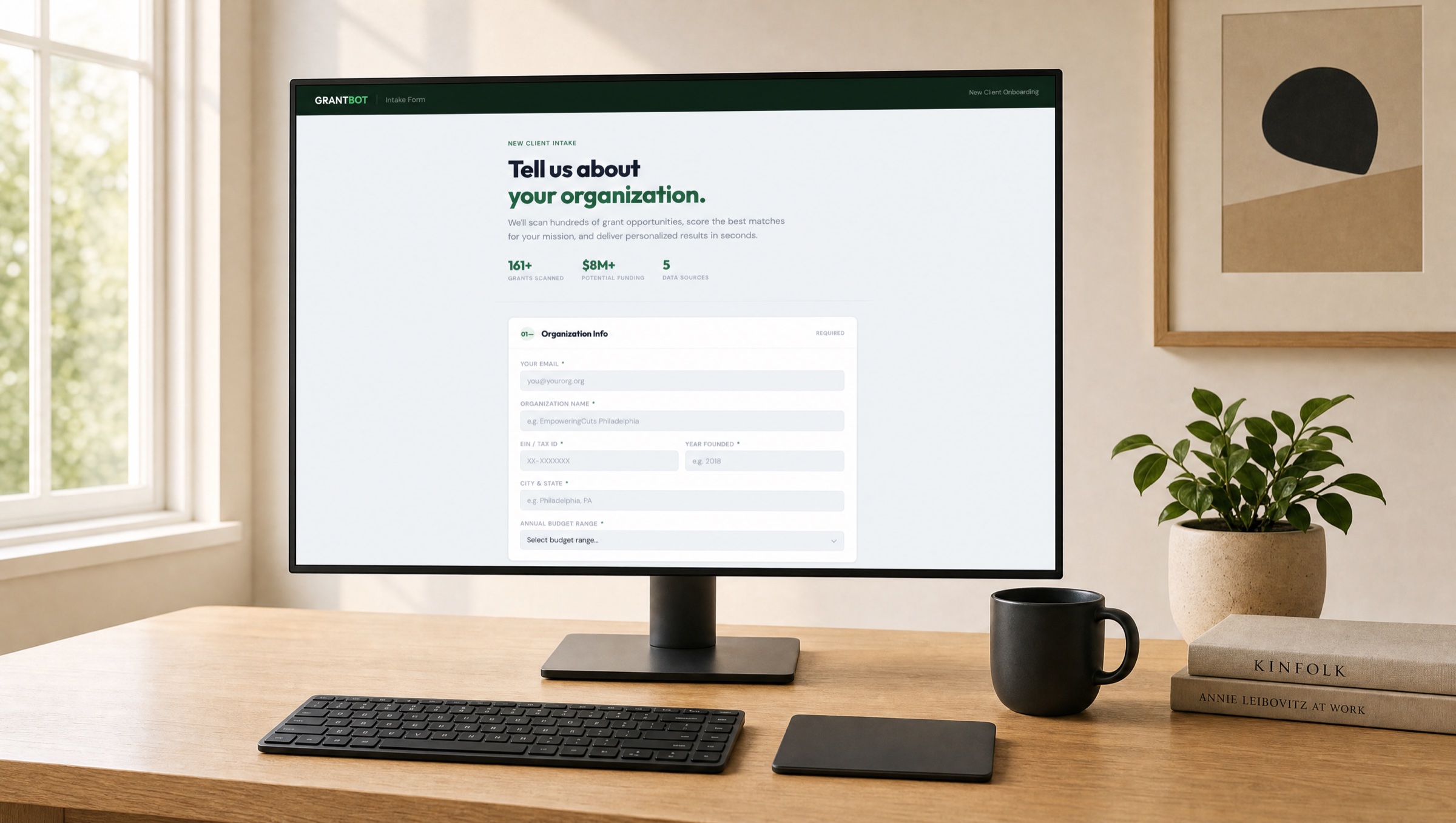
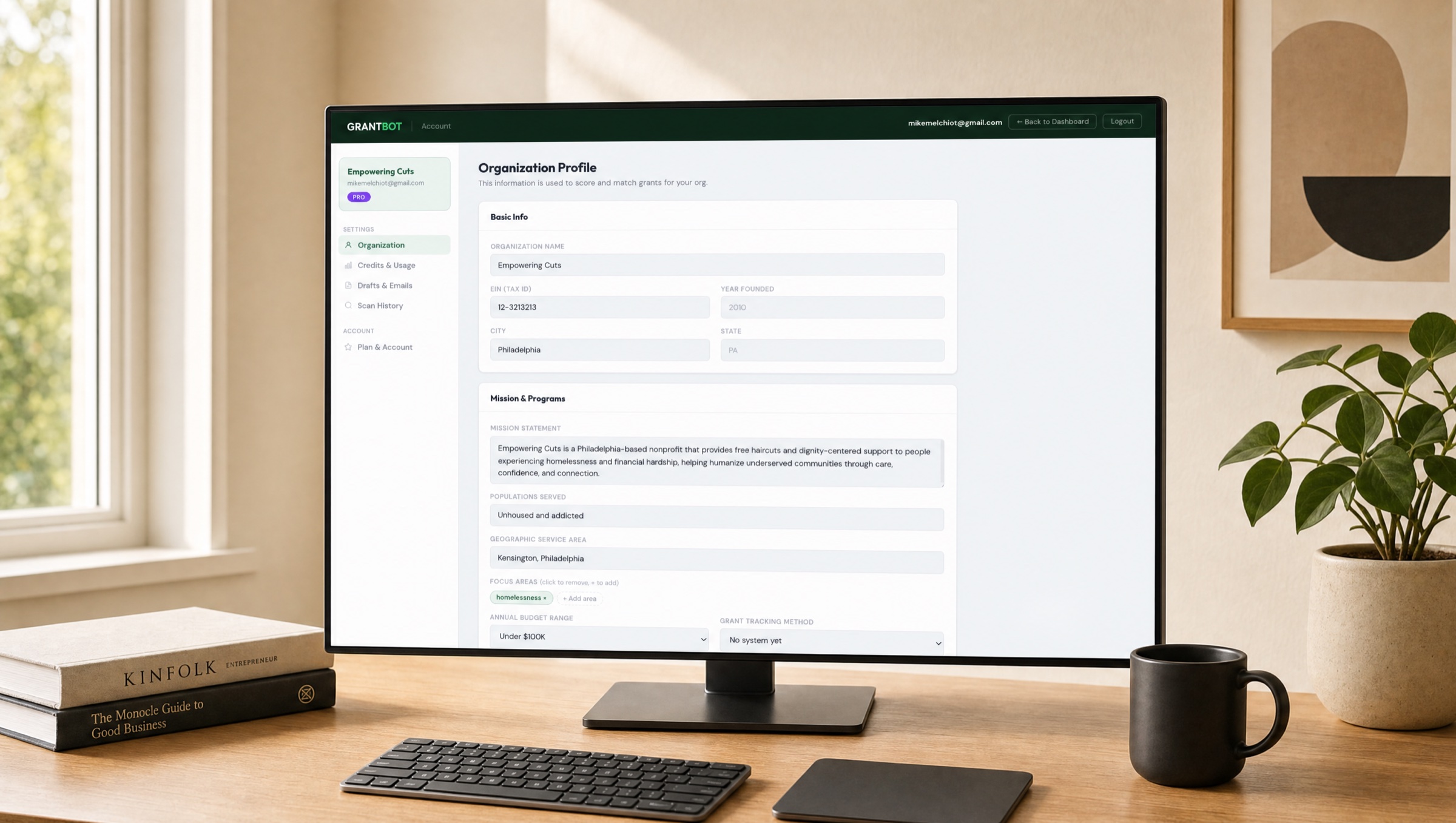
The pilot client — Empowering Cuts — runs a mobile barbershop in Kensington serving unhoused individuals. Founder is a working barber. There is no grants person. The whole organization is one person and a van.